get all the free things with python
I love getting free stuff. Who doesn’t. The problem is that there’s no reliable way to continually get free stuff. I picture a sea anonenomie, waiting for plankton to swim into its mouth as my technique for acquiring things in the past. Now however, I have identified a way to jack directly into the community of people who have excess items to get rid of. Now I am like the darwins apex sea anonenomie, free from the coral, hunting the plankton in the open ocean.
Finding that community of people who want to get rid of stuff is the easy part. In my neck of the woods there’s only 2 games in town. Facebook Marketplace and Craigslist. The choice was easy for me… I loathe facebook marketplace with a passion. So this free stuff hack is done - you really don’t need any more technology than just going to the free section of craigslist and waiting for something interesting to get posted. So you could sit there and refresh the browser endlessly OR… you could use python to do it for you. The implementation I envisioned is I run my python script indefinitely on a server at home and I receive alerts to my phone in real time as free stuff gets posted.
So there’s a library for this… here but I couldn’t get it to work for me. Looks like Craigslist has fortified their website against plain requests which is what this library is using under the hood. You get a html page that looks like it would be the correct craigslist page, except theres no posts and inside the script tag theres this message from the developers:
<noscript id="no-js">
<div>
<p>We've detected that JavaScript is not enabled in your browser.</p>
<p>You must enable JavaScript to use craigslist.</p>
</div>
</noscript>
<div id="unsupported-browser">
<p>We've detected you are using a browser that is missing critical features.</p>
<p>Please visit craigslist from a modern browser.</p>
</div>EDIT: I just pulled this error from an issue on the github repo because when I tried to reproduce it just now, I got the whole kitchen sink from craigslist - with no error!! I specifically remember getting this error 3 months ago when I was playing with this project. I will perhpas do some more investigation to see what’s going on but for now I am going to keep writing my blog post as if I didn’t see this.
I wrote this solution on an Arm macbook and then deployed it on a raspberry pi 4 running 64bit raspbian (I am informed that 32 bit doesn’t have a geckodriver or chrome driver). I wanted to practice my databasing skills so I ran a postgres database and interfaced with it using sqlalchemy. To bypass the issue above, I followed the advice of the error message and scraped it by running an actual browser with selenium.
Here is my models.py file:
from dataclasses import dataclass
from typing import Optional
# SQLAlchemy imports
from sqlalchemy.orm import MappedAsDataclass
from sqlalchemy import Column, Float, String, DateTime, Integer
from sqlalchemy.orm import DeclarativeBase
from sqlalchemy import create_engine
from sqlalchemy.orm import Session
from sqlalchemy.orm import Mapped
from sqlalchemy.orm import mapped_column
from sqlalchemy import select
@dataclass
class Config:
urls: list[str]
send_email_alerts: bool
src_email: str
dst_emails: str
email_key: str
send_sms_alerts: bool
src_phone_number: str
dst_phone_numbers: str
twilio_account_sid: str
twilio_auth_token: str
db_user: str
db_password: str
# format is postgresql://username:password@host:port/database
def get_engine(user: str = 'postgres', password: str = 'password', host: str = 'localhost', port: str = '5432', database: str = 'craigslist', echo: bool = False):
SQLALCHEMY_DATABASE_URL = f'postgresql://{user}:{password}@{host}:{port}/{database}'
engine = create_engine(SQLALCHEMY_DATABASE_URL, echo=echo)
return engine
class Base(MappedAsDataclass, DeclarativeBase):
pass
def get_db(table_name: str):
class db_listing_entry(Base):
__tablename__ = f'cl_table_{table_name}'
id: Mapped[int] = mapped_column(Integer,init=False, primary_key=True)
link: Mapped[str] = mapped_column(String)
title: Mapped[str] = mapped_column(String)
cl_id: Mapped[str] = mapped_column(String)
screenshot_path: Mapped[Optional[str]] = mapped_column(String)
time_posted: Mapped[str] = mapped_column(String)
location: Mapped[str] = mapped_column(String)
time_scraped: Mapped[str] = mapped_column(String)
def __repr__(self):
return f'link: {self.link}\ntitle: {self.title}\nid: {self.cl_id}\nscreenshot_path: {self.screenshot_path}\ntime_posted: {self.time_posted}\nlocation: {self.location}\ntime_scraped: {self.time_scraped}'
return db_listing_entryThe funkiness that is the get_db function is a result of the postgres tablename being available at runtime based on the config file passed to the script.
Then the actual script that does the scraping:
parser = argparse.ArgumentParser()
parser.add_argument('--config', default='./configs/myconfig.json',
help='pass the file path to your keyfile')
cl_args = parser.parse_args()
try:
with open(cl_args.config) as json_file:
config = Config(**json.load(json_file))
except Exception as exc:
print(
f'ERROR: check config file - something is broken.{Exception=} {exc=}. Exiting...')
exit()
name = cl_args.config.split(sep='/')[-1].removesuffix('.json')
db = get_db(f'{name}')
engine = get_engine(user=config.db_user,
password=config.db_password, echo=False)
db.metadata.create_all(engine)
error_count = 0
def browser_setup():
user_agent = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/109.0'
firefox_option = Options()
firefox_option.add_argument('-headless')
firefox_option.set_preference('general.useragent.override', user_agent)
browser = webdriver.Firefox(options=firefox_option)
browser.implicitly_wait(1)
return browser
def translate_html_elements(timestamp: str, browser):
listings = []
delay = 5 # seconds
pageLoadClock = datetime.datetime.now()
current_time = pageLoadClock.strftime("%H:%M:%S")
print("Time before starting page load =", current_time)
try:
WebDriverWait(browser, delay).until(
EC.presence_of_element_located((By.CLASS_NAME, 'cl-search-result')))
pass
except TimeoutException:
pass
pageLoadedClock = datetime.datetime.now()
current_time_after_page_loaded = pageLoadedClock.strftime("%H:%M:%S")
print("Time after page load and before clicking the Try it button=", current_time_after_page_loaded)
free_elements = browser.find_elements(
by=By.CLASS_NAME, value='cl-search-result')
for el in free_elements:
a_tag = el.find_element(by=By.CLASS_NAME, value='titlestring')
title = a_tag.text
link = a_tag.get_attribute('href')
cl_id = link.split(sep='/')[-1].removesuffix('.html')
meta_string = el.find_element(by=By.CLASS_NAME, value='meta').text
posted_time, location = meta_string.split(sep='·')
result = db(link=link, title=title, cl_id=cl_id, screenshot_path='',
time_posted=posted_time, location=location, time_scraped=timestamp)
listings.append(result)
return listings
def scrape(url: str, timestamp: str):
global error_count
browser = browser_setup()
browser.get(url)
num_listings = 0
# get all list items
with Session(engine) as session:
try:
listings = translate_html_elements(timestamp, browser=browser)
except Exception as exc:
browser.quit()
error_count += 1
print(
f'ERROR: {exc=}\nScript will try {3-error_count} more times and then shutdown.')
send_error_alert(
f'ERROR: {exc=}\nScript will try {3-error_count} more times and then shutdown.')
if error_count == 3:
send_error_alert(
f'ERROR: {exc=} - Ask silas to restart the script.')
exit()
return
browser.quit()
num_listings = len(listings)
for listing in listings:
if not session.query(db).filter(db.cl_id == listing.cl_id).first():
# remove this monstrosity and reaplce with the ** operator,
# entry = db(cl_id=listing.cl_id, link=listing.link, title=listing.title, screenshot_path=listing.screenshot_path,
# time_posted=listing.time_posted, location=listing.location, time_scraped=listing.time_scraped)
print(f'\tADDED {listing}')
session.add(listing)
# session.add(entry)
# session.add(db_listing_entry(**dict(listing)))
# else:
# print(f'\tCOLLISON: {listing.title}, {listing.cl_id=}')
print('commiting to db')
session.commit()
return num_listings
def welcome_message():
print(f'''
Welcome to the craigslist free alert searcher.
Every 3 minutes this script will query cl for free items and then print the new items to the terminal.
cheers!
''')
def send_email_alert(alert):
msg = EmailMessage()
msg['Subject'] = f'cl item alert'
msg['From'] = config.src_email
msg['To'] = config.dst_emails
msg.set_content(alert.to_json())
ssl_context = ssl.create_default_context()
with smtplib.SMTP_SSL("smtp.gmail.com", 465, context=ssl_context) as server:
server.login(config.src_email, config.email_key)
server.send_message(msg)
def send_error_alert(error: str):
client = Client(config.twilio_account_sid, config.twilio_auth_token)
client.messages.create(
body=error,
# body=message_body,
from_=config.src_phone_number,
to=config.dst_phone_numbers
)
def send_sms_alert(alert):
client = Client(config.twilio_account_sid, config.twilio_auth_token)
message_body = f'title: {alert.title}\nscraped: {alert.time_scraped}\nposted: {alert.time_posted}\nlocation:{alert.location}\n{alert.link}'
print(message_body)
client.messages.create(
body=message_body,
# body=message_body,
from_=config.src_phone_number,
to=config.dst_phone_numbers
)
def send_alert(alert):
# if bool(config['send_email_alerts']):
# send_email_alert(alert)
if bool(config.send_sms_alerts):
send_sms_alert(alert)
def sleep_random(lval, rval):
seconds = random.randint(lval, rval)
timestamp = datetime.datetime.now() # .strftime('%Y-%m-%d %H:%M:%S')
next_iteration = timestamp + datetime.timedelta(seconds=seconds)
print(f"{timestamp.strftime('%Y-%m-%d %H:%M:%S')}: sleeping for {seconds//60} minutes and {seconds%60} seconds..., next request at {next_iteration.strftime('%Y-%m-%d %H:%M:%S')}")
time.sleep(seconds)
def main():
# begin scrape loop:
intial_loop = True
while True:
# get results
timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
for i, url in enumerate(config.urls):
# returns the number of new listings
scrape(url, timestamp)
if intial_loop:
continue
with Session(engine) as session:
listings = session.query(db).filter(
db.time_scraped == timestamp)
for i, listing in enumerate(listings):
print(f'{i}. {listing.title} : {listing.link}')
send_alert(listing)
# sleep before we get the next url result
if i != len(config.urls) - 1:
sleep_random(5, 15)
intial_loop = False
# sleep between 3 and 6 minutes
sleep_random(45, 90)
if __name__ == "__main__":
main()Where the config file looks like:
{
"urls" : [
"https://seattle.craigslist.org/search/seattle-wa/zip?lat=xx.xxxx&lon=-xxx.xxxx&search_distance=x.x#search=1~gallery~0~0"
],
"send_email_alerts":"False",
"src_email": "",
"dst_emails": "",
"email_key": "",
"send_sms_alerts":"True",
"src_phone_number" : "",
"dst_phone_numbers" : "",
"twilio_account_sid" : "",
"twilio_auth_token" : "",
"db_user": "",
"db_password": ""
}The url in the config file comes from going to the craigslist website and using their GUI to refine your search, in my case I used the map to circle a radius of 5.1 miles around my neighborhood. Any farther and I received way too many text messages.
I noticed while running this script that Craigslist batch posts ads with the rollout distributed instead of being universally available for everyone all at once. Looks like they post the ads about every 15 minutes or so, and I have seen posts on my phone posted up to 3 minutes before my bot notifies me that they’re available and vice versa. So it’s not quite fish in a barrel when trying to get an item, there’s still some lottery luck that plays into it. After missing out on a TV I wanted, I made an iOS shortcut that will allows me to use a template to send emails so I can be that much faster and have that much more likihood of being the first emailer.
I’ve had trouble sharing the shortcut so i’ll just include a screenshot of it so you can replicate it yourself.
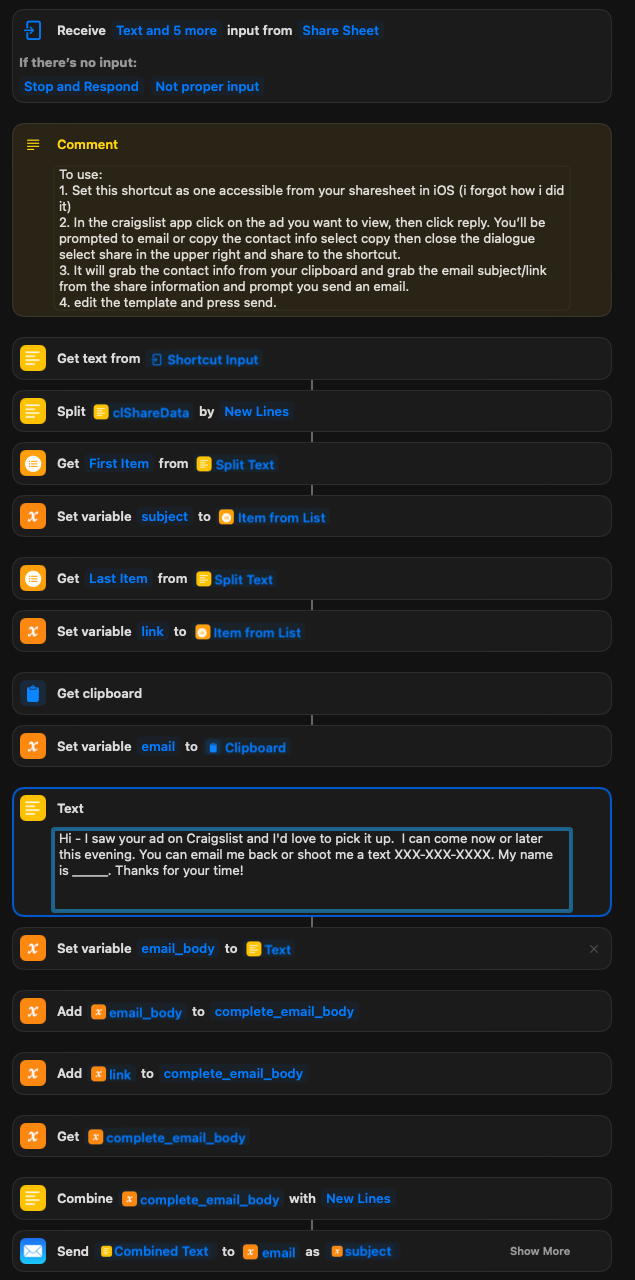
Now I finally am the junkyard king of my neighborhood in seattle. If I see something that gets posted - I will have it. Since running the bot paired with my shortcut, I have only fumbled one connection. Usually I get a response that looks like this, which I receieved in response to picking up a Sony OLED 55XBR TV:
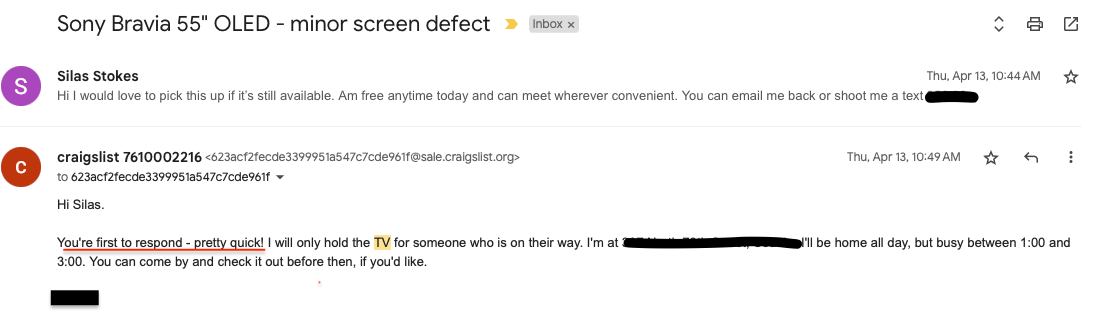
Note the “you’re the first to respond - pretty quick” - when I tell you I felt smug, oh boy… This is how the people who used a bot to get a 4080 during the GPU crisis must have felt.